

If you are managing a pharmaceutical, chemical or any process manufacturing operations and wanted to collect data from your process machines and operations, chances are you are either dependent on vendor of the process machine to access your data, its archival or backup. Often the data portability strategy is missing from vendors’ offering or data generated by process machine is locked within the proprietary formats. Most often the challenge is that this data is lost after a certain accumulation time (in few hours or days) as the computing and data storage infrastructure on the process machine is very lean and not enough to accommodate large amounts of process history.
The onsite industrial automation team often struggles to connect, collect and consume data in real time from their process machines controllers or SCADA systems. The absence of enough computing infrastructure from the operational technology landscape makes it difficult to create unified, integrated applications that can serve the data in a no-code or low-code environment to the IT challenged automation engineer or plant supervisors. Engineers supporting a chemical or pharmaceutical process desire a simple solution that can:
- Collect and store their operational data with long-term history, regardless of OEM vendor diversity from their process machines.
- Access to this data in a non-programmatic way in a simple spreadsheet format
- Capability to set complex domain specific alerts, aggregated or derived parameters
- Trend historical data w.r.t time or batches
- Perform context based (batch, phase, events, alarms) aggregations and comparisons of raw and aggregated data with respect to these events.
Any modern process data historian should be able to not only provide access to long term process history of machine sensor data, but it should also be able to slice and dice the historical data to provide on-demand and in real-time event and batch durations and associated data aggregations or comparisons arising from this slicing and dicing of data. Figure 1 below shows the contextual hierarchy that any data historian should support out-of-the-box to be able to serve the needs of process engineers mentioned in five desired items above. Figure 1 also shows the aggregation complexity that any data historian should handle in real-time so that it can provide the necessary aggregation functions to raw sensor streams covering the full contextual hierarchy spectrum.
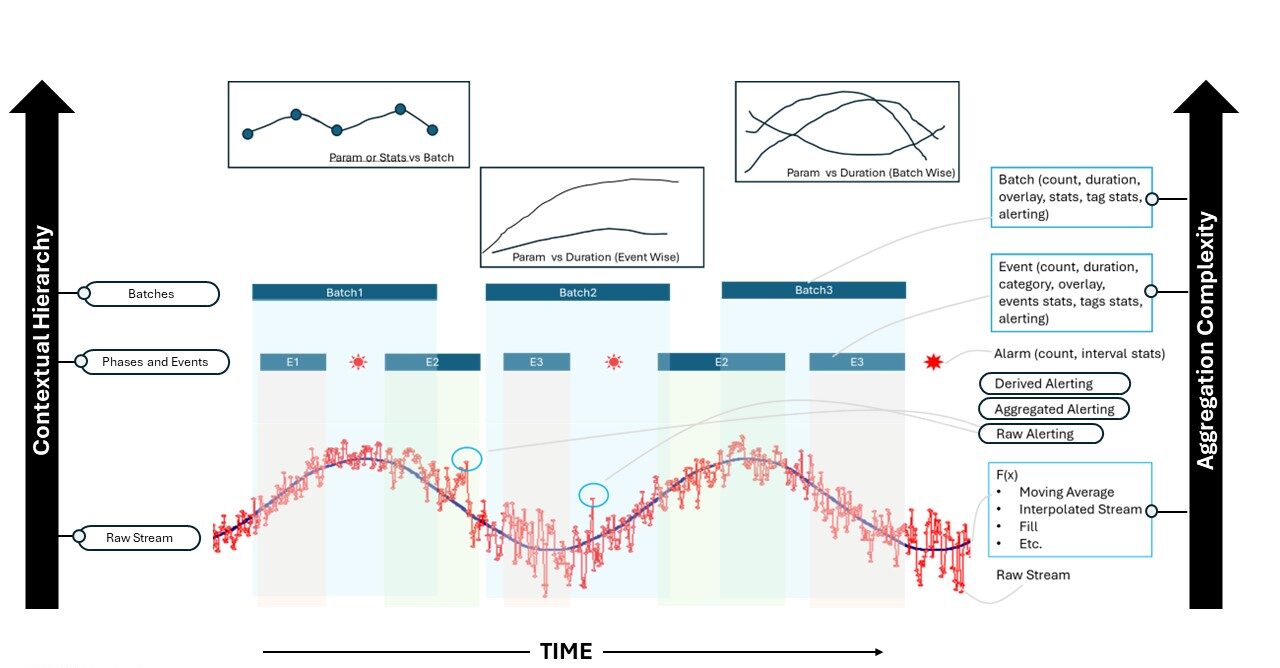
Figure 1: Desired Historian Basic Functions
Factorian edge computing platform provides such an out-of-the-box plug-n-play experience to connect, collect and consume process historical data both from process machines as well as any execution systems like MES and LIMS.
A time series historian collects and stores extremely large amounts of data. The scale of volume of data can be assessed from these calculations below even for a small historian of 1000 tags (Note: a ‘tag’ is a process parameter like temperature or pressure captured by a sensor on the process machine that is tagged as a ‘tag’ on an industrial automation SCADA or control system). If the data collected into these tags from source is at 1 second frequency, then for a 1000 tag historian system the total number of data records collected in one day is 86400×1000 = 86400000. This translates to roughly ~ 86 Million records per day. Over the year, this data translates to 31 billion records, which on an average corresponds to roughly (assuming each sensor data along with its timestamp and context occupies 100 bytes of information to be stored) 30 Terabytes of data per year. This can easily translate into petabytes of data as our number of tags scale and/or when we wish to store multiple years of data.
Traditionally, most of the process historians built in late 1990’s store data in files as traditional RDBMS type databases like MS-SQL or MYSQL are not efficient to perform read/write operations for such large high frequency time-series data. File system read/write provides much better performance than an RDBMS. However, this required most of these traditional historians to down-sample data using various “lossy” compression algorithms (for example Swinging Door algorithm) to achieve an optimum performance between data retrieval, archival and storage. But this requires careful inspection of tag tuning parameters for each tag to evaluate fidelity of compression, which is not a trivial pursuit.
With the recent advent of columnar time-series databases, this traditional approach of “lossy” compression and file system storage can be eliminated with these more efficient and convenient databases that are designed for storing large amounts of time series data with lossless compression techniques. Also, with the availability of high capacity (>1 TB) solid-state flash drives like NVMEs that has extremely high I/O rates, the time is now right to transition to a more hardware optimized historian.
Another area where traditional historians give IT departments headaches is in management of its backups and while performing system and software upgrades. The hardware sizing and upgrades in the traditional historians is a big planning task and prone to a lot of pain and nightmares during transitions. Adding to this complexity is the management of add-on enterprise features like redundancy and HA (High Availability) servers and their respective backups and upgrades.
The application containerization (for example Dockers or Pods) provides a much-needed solution for the above problems associated with maintenance and life-cycle management of historian databases. The ability to scale these columnar time-series database in the form of cluster nodes and the ability to shard the data into parts while writing data into a cluster of small physical computing hardware nodes along with creating necessary replications within these nodes not only provides efficient storage but also necessary redundancy and high availability by default. This also provides easy maintenance and upgrades of the underlying hardware system, which enable replacing the underlying physical hardware nodes infrastructure one at a time while the clustered historian application keeps running with no down-time.
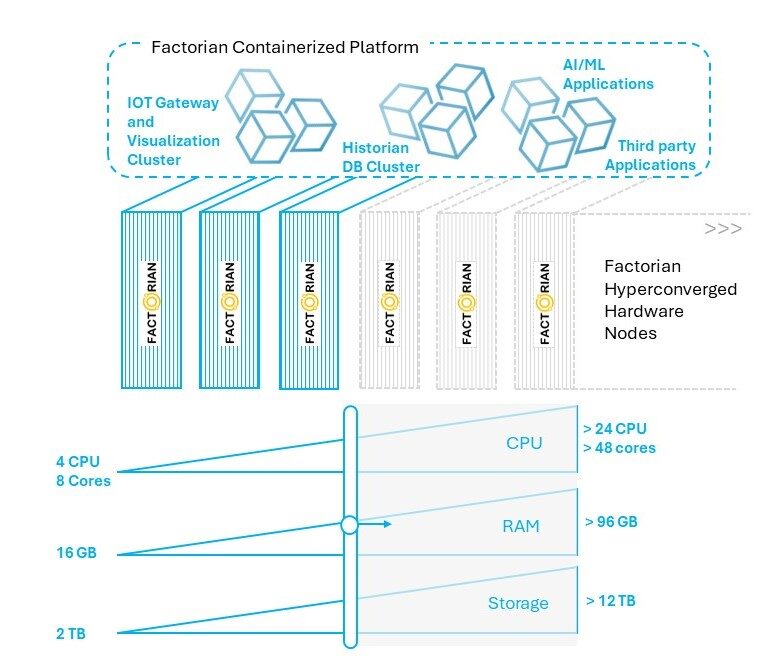
Figure 2: Factorian Edge Historian Platform
The “Hyperconverged Infrastructure” is a key enabler for creating such an always-on highly available, fault tolerant and storage efficient system, mimicking a cloud like elastic environment within a secured factory premises. This hyperconverged infrastructure can easily be hosted on rugged and inexpensive industrial fan-less PC’s that can run on a wide operating temperature range (-20DegC to 50DegC) making a stack of these nodes installed on a small server rack or even a DIN rail cabinet negating a need for an expensive full-fledged data centre. Figure 2 above shows how a historian platform based on hyperconverged hardware nodes helps with horizontal or vertical scaling. The container orchestration environment hosted on the nodes running on this hyperconverged infrastructure manages and abstracts the underlying computing resources, persistent storage and cluster network of hardware nodes. Factorian edge computing historian infrastructure is designed in such a way where the Factorian orchestration software, its historian database and the underlying hyperconverged hardware are delivered as an easy to manage plug-n-play platform.
For more info reach out to us!