

Streaming data access from industrial machines has traditionally always been a very tedious and stressful affair that not only involves tons of components to manage but also involves complex coordination with instrumentation or automation engineers, networking engineers and site or corporate IT. Building of these data access pipelines that pushes data from machine sensors all the way to the end users in the form of real-time trend charts or tabular reports involves many layers of independent software, hardware, networking components along with tedious life-cycle management of these systems. Over and above these, organizations have to deal with training and support of each of these individual components involved.
Most often these components don’t come as one single interface or from a single vendor and managing them becomes a nightmare for any support function within the organization. Added to this complexity is the multidisciplinary nature of these data pipelines that makes it more challenging when we see a constant churning or shortage of trained manpower in modern organizations. Sustainable and robust maintenance of these pipelines to constantly keep the seamless flow of contextual data from machines to the end user in the right format becomes a very stressful and resource intense activity. Organizations often hire an army of interdisciplinary engineers to keep the pipelines alive for process engineers and scientists to have real-time access to process data for timely action on process deviations to gain significant supply chain productivity gains.
Different layers of hardware, software, and manpower systems that are involved in creating such a data infrastructure is shown in Figure 1 below.
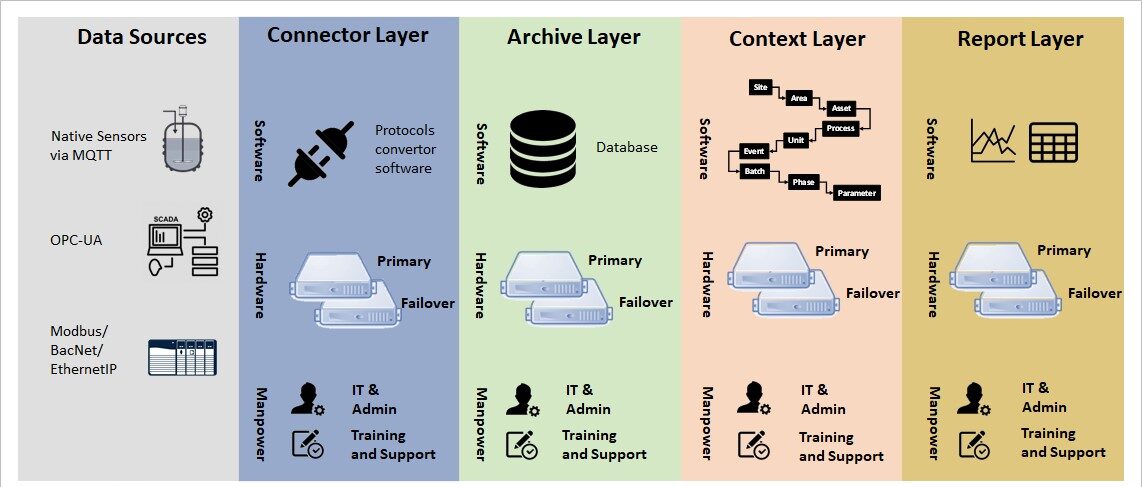
Figure 1: Components currently needed to fetch data from Industrial Process Machines
As we can see in Figure 1 there are many layers involved with various software, hardware and manual components that needs to be managed at each layer to provide smooth data flow from the data sources all the way to the hands of the end user (process engineer). The four main layers of these data pipelines are as follows:
- Connect layer: This involves managing a protocol converting software that can convert and read sensor data from systems communicating from various industrial protocols like MODBUS, Ethernet/IP, Profinet, OPC-DA or OPC-UA. Not only the software needs special tools/connectors to connect to these systems, it should be programmed to convert those protocols to standard IT languages and protocols so that databases can ingest this data efficiently or real-time alerts can be sent in human readable form to the end user.
- Archive layer: Traditional RDBMS databases like MySQL, SQL Server or Oracle databases cannot handle streaming data ingestion and efficient storage of time-series data, hence, special time-series databases need to be installed that can not only ingest the data at high speed and archive them but also are able to serve the data at high speed for real time OLAP (online analytical processing) queries. These special requirements are rarely met and make this layer the most critical piece (or rather bottleneck) in providing real time streaming or on-demand access to end users. Traditionally industrial data historians like OSI-PI or GE-Proficy have been filling this space, and we all know managing these types of software is not easy and requires an army of engineers to keep them running throughout the life cycle of these products.
- Context layer: The data stored in the archive layer efficiently captures the time-series data for long term, however, this data is only timestamped raw numbers from various process machines. They don’t contain any processing environment context within which the data was captured, for example, the timestamped raw data belongs to which site or location or which manufacturing process or batch event. To link this process execution contextual information this context layer is needed that require another set of software tools that needs their own set of independent hardware and software life cycle management.
- Report layer: Once we have all the three layers (Connect, Archive and Context) in place, another important layer is needed that can now combine raw data stored in “Archive layer” with the processing context available from “Context layer” to serve it to end user as charts and tables in a real-time streaming manner or on-demand for process analytics. This layer again requires another set of software tools with its own set of independent hardware and software life cycle management.
The skills required at each layer are very different both in terms of life cycle management, but also in terms of hardware resources or computing power needed to serve the customer in real-time. Currently, all these layers run on independent servers (either physical or virtual) within data centres and organizations have to make their own arrangements to configure them for redundancy or run in highly available mode so not to miss any heartbeat from any process machine or lose any data. This makes the whole system of these four layers a management nightmare and takes a heavy toll on overall TCO (total cost of ownership) and long-term sustainability.
Now in the Industry 4.0 era, real-time access to SCADA or machine sensors is to become more prominent and a critical component of the control strategy of manufacturing operations. Hence, solutions are needed to drastically simplify the deployment and life-cycle management of the systems involved in these real-time streaming machine data pipelines so that organizations can focus more on their core businesses rather than firefighting and managing on data connectivity or provisioning of computing resources.
Factorian edge computing platform is a unique offering that tries to ease or eliminate this complexity by providing a cluster of plug and play edge devices that can bring all these components explained above into one single subscription service as shown in Figure 2.
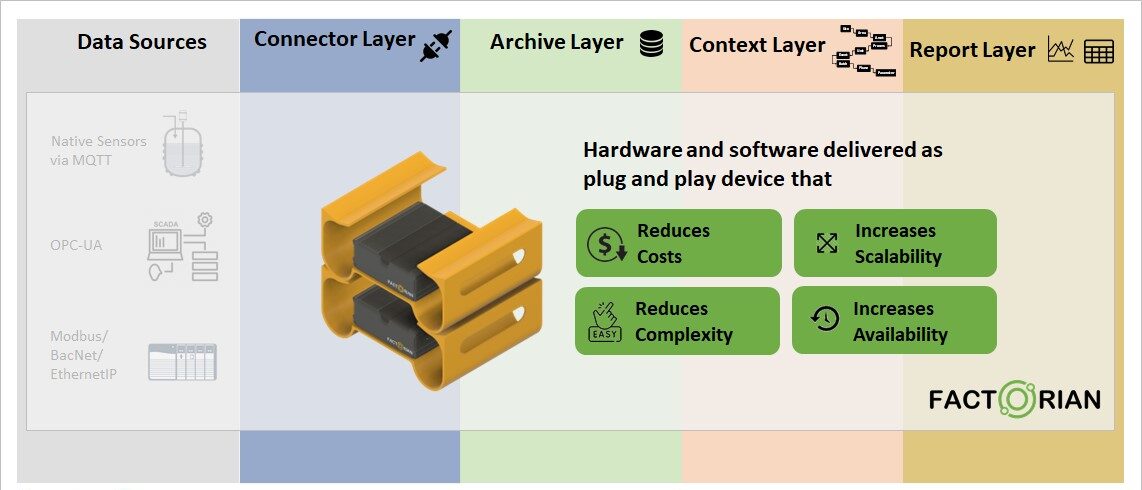
Figure 2: Advantages of Factorian edge platform for machine data access
The platform runs on our ruggedized commodity hardware devices without the need for running them in faraway dedicated data centres in controlled environments, but instead can be setup within the plant manufacturing floor or the process development labs itself. The devices can be simply stacked over each other to auto scale for additional compute power or storage needed as new assets are on-boarded. Furthermore, each device stack is pre-programmed to serve as a cluster that provides fault tolerant, highly available mode of operation to execute the data pipelines from source machines all the way to end users in real-time. All the software and hardware needed in the four layers to extract data from source machines and serve it to the end users in the contextual form is provided as a plug and play service. All the devices and software/server clusters that run within these devices are delivered as one single annual fully serviced subscription.
To find out more about Factorian platform and our offerings, please contact us or schedule a call.